This article is part of a miniseries:
- Learning Rust with Large Language Models (Part I): a Project for 2024.
- Learning Rust with Large Language Models (Part II): an Outdated Manual Written by a Newbie.
- You’re reading it.
There’s a GitHub repo associated with this series. You can find more fine-grained examples of the interactions there. And another one for the capstone project.
The internet keeps bombarding me with two different takes on programming with LLMs: the best thing since the advent of sliced bread that most engineers use to write production code; or a statistical abomination that arguably makes you dumber. It’s bimodal.
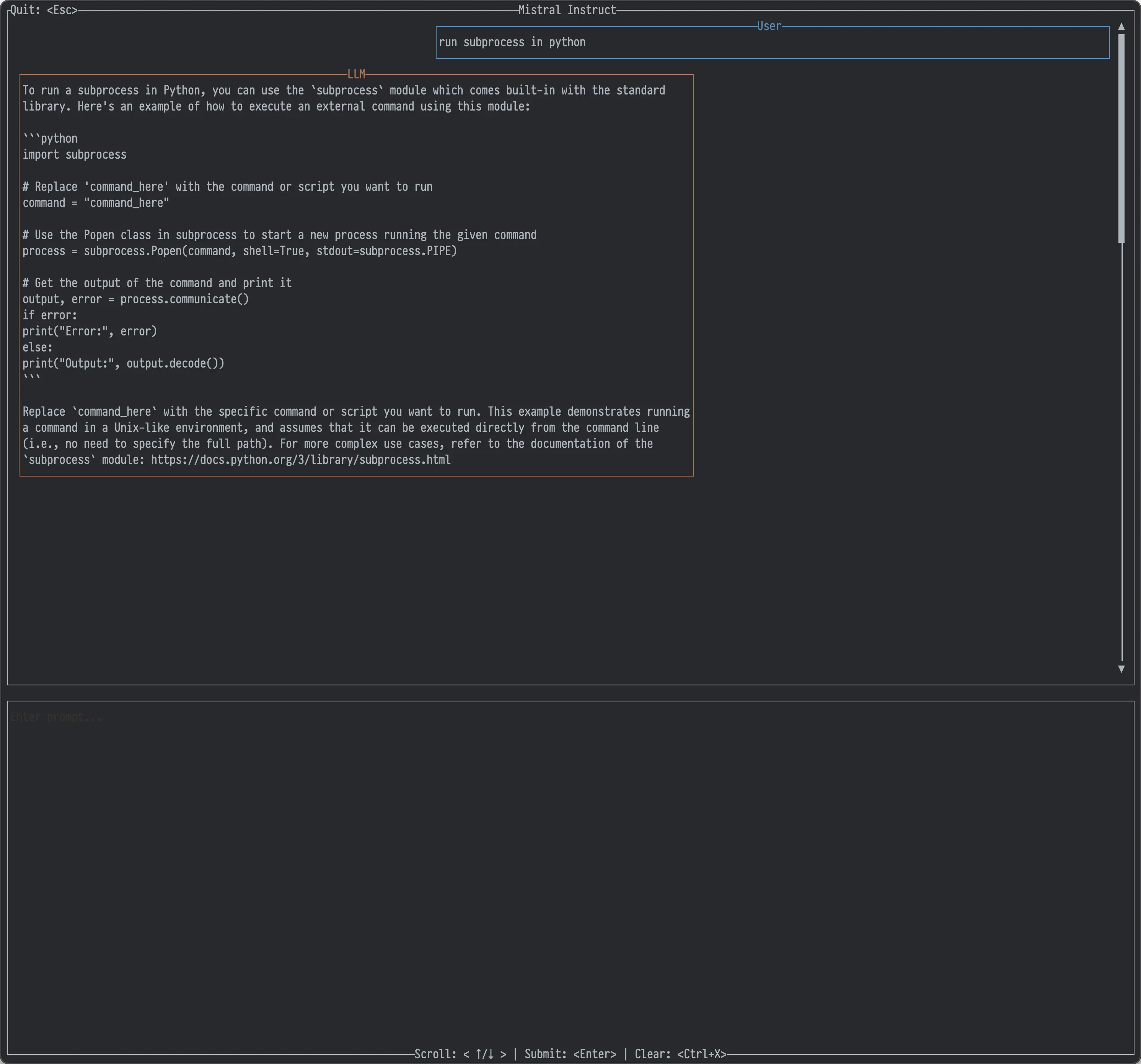
By the way, I’m not going to talk about the code I wrote in this part of the series. It mostly followed the plan from my first post; you can check it out in the associated repo:
- some basic async wrapper around a database, exposed via a web server,
- maturin-based rust bindings for Python,
- a neat terminal-based LLM chat (ironic, I know).
Disclaimer: findings based on ChatGPT-4(o).
Old friends anew
One notable difference between my last post and this one is that I used GPT-4(o), instead of 3.5. If you were hoping that this upgrade would reasonably address some, most, or all of my complaints from the last post, then you were right!
I wish ¯\_(ツ)_/¯ generation is slightly faster. I still get to stare at the model generating tokens, waiting for it to finish. I don’t know how other people read code or structured text but I first skim the overall structure/outline, and then, read the details. Autoregressive generation doesn’t allow this unless you wait until the LLM is done generating. While there are ways to make it really fast — groq does it — major providers don’t.
It still hallucinates and gives me code that just doesn’t look right. To be fair, I don’t know how to quantify this. I don’t keep exact records of how many times something was incorrect, or the degree of how incorrect it was. It feels slightly more consistent but not enough to just fire and forget.
Worst of all, despite more recent training data cutoff, it still doesn’t know about recent libraries.
Having said that, the ability to refine what you mean, and steer the model (I coined the term contextual refinement in my last post), remains great. It’s the best feature of the entire LLM space. It’s like tweaking your search engine query but with both positive and negative examples.
Knowledge cutoff: 1000 BC
To put it bluntly, if you’re interested in using LLMs for newer topics, you are pressing your luck. Way too often, I get weirdly outdated information: old APIs or tools that didn’t exist at the time of training, old practices. Not on a consistent basis either, e.g. one response uses the version X of an API, and then another uses Y.
If you’ve been following this space, then you must have heard about Retrieval Augmented Generation (RAG). In a nutshell, you retrieve information related to the prompt (from some information storing database, or documents that you provide), and put it in LLM’s context. Then, you pray that in-context learning works its magic, and the LLM generates the response based on that information. Sometimes it works, sometimes it doesn’t.
As of today, July 2024, I think that LLMs — no matter how big, or trained on how much data — are merely a text generation engine that must have some external component to keep them up to date. I’m convinced that they have to be augmented with knowledge bases and/or web search via RAG or whatever else we come up with.
UX prototype
I’ve come to realise that the chat library-style UX just doesn’t work for me for any serious amount of work. Yeah, it’s nice for demoing things, and small snippets. But the more you use it, the clunkier it gets.

One giant chat for all things rust? You have to scroll through pages of text to find something from two days before. It slows down inference too. New page for each topic, or a couple? You need some system to figure out which chat has what information. ChatGPT doesn’t have a search for your chats. In itself, it’s funny that the internet tells me that LLMs are replacing all kinds of search, while I need search for my LLM chats. Better yet, let’s search through LLM chats with an LLM /s.
And while I’m beating a dead horse here, having to fall back on the search engines when the information is outdated is pretty bad UX too. It just discourages me from using the LLM in the first place. I want it to be less effort than using a search engine. Otherwise, what’s the point?
Mad genius
Surely, you’ve noticed that this article has been nothing but a balanced compilation of pros and cons. In case you haven’t, I’m going to give you another positive take.
Sometimes, it just works™️ — great response with minimal effort, and my jaw drops to the floor. I was struggling with some lifetimes in my rust code; ChatGPT just figured it out, and gave me sound explanations. I needed to migrate some files and couldn’t be bothered to write a shell script to do it because it’d take two hours. Merely twenty minutes with ChatGPT after a bit of sketching it out. Hence, the titular needle in a haystack.
Every time it happens, it makes me question my experience. Am I thick and can’t use it properly? Maybe I’m too critical of the variable quality of the responses. Or are some people’s standards so low, or tasks so simple that ChatGPT is consistently doing a good enough job?
To quote principal Skinner “Am I out of touch? No, it’s the children who are wrong”.
Value for money
What I’d like you to take away here is that I haven’t found ChatGPT all that useful for learning rust. Just because it didn’t work well in this restricted exercise, it doesn’t mean that it’s entirely devoid of value. I still use it occasionally for shell scripting, plotting in matplotlib, or just getting a feel for an engineering topic that I’m not familiar with.
Buuut, not useful enough to continue paying €25/month for it. I think it’s more of a feature of an operating system, or an application, than a standalone product. Hence, I’m looking forward to how they get packaged into more complete solutions, and what this space would be like a couple of years from now.
In the meantime, I’m going to continue using the free variant of ChatGPT and my own TUI app.